Regular Expression
Make each program do one thing well - The Unix philosophy
概述
什么是正则表达式
有种标准叫做正则表示法,你可以依据该标准写出一些特殊的字符排列,叫做正则表达式
你可以利用正则表达式高效准确地匹配并处理一个或多个字符串
简言之:正则表达式就是一种处理字符串的方法
要想使用正则表达式,必须使用支持正则表达式的软件工具,比如 vim、grep、sed、awk、…
正则表达式的广泛用途
对于个人而言,使用正则表达式,能让你在使用主机时更精简高效地处理日常事务 !
比如:
当你使用编辑器之神 vim 编辑文本时,要想把「搜索/删除/替换」等动作做得漂亮,就需要配合使用正则表达式
再比如:
你的系统在繁忙时会生成成千上万行的信息,这些信息往往由极其重要的信息和无关紧要的信息杂糅(重要的信息比如:错误信息、系统被入侵的记录信息、…);要想成为一个合格的系统管理员,你就应当学会编写、学会利用正则表达式从这大量的信息中快速提取出重要信息,甚至输出生成便于查阅的报表,以此来方便自己
此外,由于正则表达式强大的字符串处理能力,有很多软件都支持正则表达式,有很多软件都使用正则表达式来实现一些功能
比如邮件服务器就使用正则表达式分析并过滤垃圾邮件
具体是怎么做的呢 ?
答:
- 由于垃圾邮件几乎都有标题或内容
- 因此,邮件服务器只需利用写好的正则表达式,就能对收到的信件的标题和内容进行字符串匹配
- 如此,垃圾邮件们就能被过滤出来,进而被剔除
自然这些邮件就不会被发送到用户端,既节省了用户的流量带宽,也规避了很多麻烦
啥 ?你觉得你会 ctrl+f 就够 ?
那我问你,假如你只想找到 VBird 或 Vbird 这个关键词(一个字母都不能差,大小写也不能差)
你咋办 ?
就拿被广泛使用但其实一点也不哇塞的 MS word 来举例,它并不支持正则表达式
显然,你需要分別以 VBird 和 Vbird 搜索两遍
或者你可以启用忽略大小写的功能,但这就会匹配出你不需要的关键词,比如 VBIRD、vbird、…
看吧,不支持正则表达式有时就很麻烦,但若用上正则表达式,这个需求就会和探囊取物一样简单
再举个例子
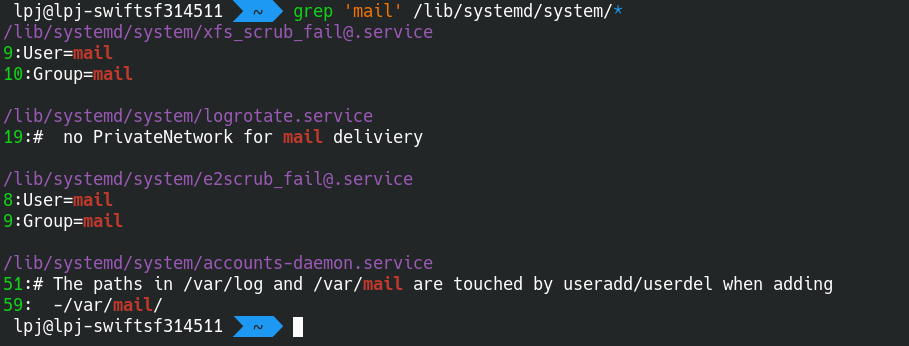
假如在系统开机的时候,总会出现一个与 mail 关键词相关的错误提示
这很令人别扭对吧 ?
你知道开机过程中的相关程序都放在 /lib/systemd/system/ 目录下,也就是说,在该目录下的某个文件中肯定有 mail 这个关键词
于是你想把这个不安分的文件“捉出来”,编辑它、修好它
你该怎么做 ?
你当然可以进入 /lib/systemd/system/ 目录,然后逐个文件地打开并搜索关键词 mail
但这个目录下很可能有大量文件 !
比如这个目录下可能会有 20 个文件,你愿意一个一个地打开搜索 ?
啥你愿意 ?你当求婚呢你愿意
假如该目录下有 100 个文件,不愿意一个一个地打开搜索了吧 ?!因为这 太 ! 慢 ! 了 !
如果你不会正则表达式,你的心情就可能是这样的
但如果你会用正则表达式,只需一行指令就找出来啦 !
1 | grep 'mail' /lib/systemd/system/* |
再次强调:
只要一个软件工具支持正则表达式,那么就可以用该软件工具配合正则表达式来处理字符串
比如 vim、grep、awk、sed、… 这些软件工具,由于它们支持正则表达式,所以可以用这些软件工具配合正则表达式来处理字符串
而像 ls、cp、… 这些软件工具,由于它们不支持正则表达式,所以它们只能使用 bash 的万用字元(wildcard)
正则表达式 ≠ bash的万用字元 !这很重要 !!!
延伸型正则表达式
正则表达式分为「基础正则表达式 & 延伸型正则表达式」
对于延伸型正则表达式,除了做简单的一组字符串处理之外,还可以做群组的字符串处理
比如:当你想要搜索 VBird 或 netman 或 lman(注意是 或「OR」 而不是 和「AND」 ),你就需要使用延伸型正则表达式了
借助(和|等特殊字元的帮助,就能实现这样的目的
虽然本文主要介绍基础正则表达式…
编码方式对正则表达式的影响
众所周知,计算机只能存储 0 和 1,电脑屏幕上显示的「数字、文字、…」都是由一些 0 和 1 根据某种编码方式映射转换而来
编码方式不同,正则表达式的执行结果就有可能不同
以英文大小写的编码为例,zh_TW.big5 和 C 这两种编码方式的编码顺序如下
1 | LANG=C => 0 1 2 3 4 ... A B C D ... Z a b c d ...z |
我们可以清楚地看到:这两种编码方式的编码顺序是不同的 !
假设你想要提取大写字母,使用了[A-Z],你就会发现 LANG=C 时确实可以提取大写字母(因为是连续的)
但若 LANG=zh_TW.big5,你就会发现小写的 b-z 也被提取了出来…
这就是不同编码方式的不同编码顺序所造成的影响
因此:
使用正则表达式时,需要特别注意当时环境的编码方式是什么,否则就可能会发现与别人不同的执行结果 !
准备工作
- 基于适合 POSIX 标准的编码方式
1 | export LANG=C; |
- grep 若不带高亮,则设置高亮
1 | alias grep="grep --color=auto" |
- 下载本文练习用的文档
1 | wget https://gitee.com/pj-l/static/raw/master/regular_express.txt |
基础正则表达式
一些特殊符号
| 特殊符号 | 代表意义 |
|---|---|
| [:digit:] | 代表数字,即 0-9 |
| [:xdigit:] | 代表十六进制数字,因此包括 0-9, a-f, A-F |
| [:lower:] | 代表小写字母,即 a-z |
| [:upper:] | 代表大写字母,即 A-Z |
| [:alpha:] | 代表英文大小写字母,即 A-Z, a-z |
| [:alnum:] | 代表英文大小写字母和数字,即 A-Z, a-z, 0-9 |
| [:blank:] | 代表「空格键、Tab」 |
| [:graph:] | 代表除了「空格键、Tab」外的其它所有按键 |
| [:space:] | 代表能产生空白的字元,比如「空格键、Tab、CR、…」 |
| [:print:] | 代表任何可以被打印出来的字元 |
| [:punct:] | 代表标点符号(punctuation symbol),包括「# ‘ “ $ …」 |
| [:cntrl:] | 代表控制按键,包括「CR、LF、Tab、Del…」 |
一个好习惯是:用
[:lower:],不用a-z,因为前者意思更明确(其它正则表达式同理)
练习笔记
如果我不想要开头是英文字母
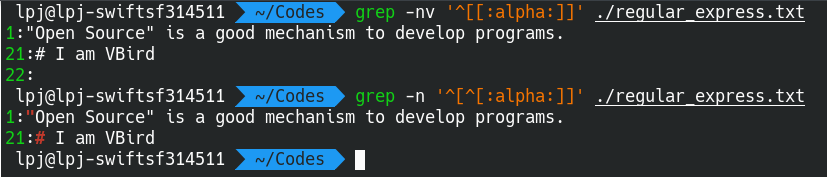
那个
^符号,在字元集合符号[]之内与之外是不同的 ! 在[]内代表「反向选择」,在[]之外代表「定位在行首」
如果想寻找空行(hang)
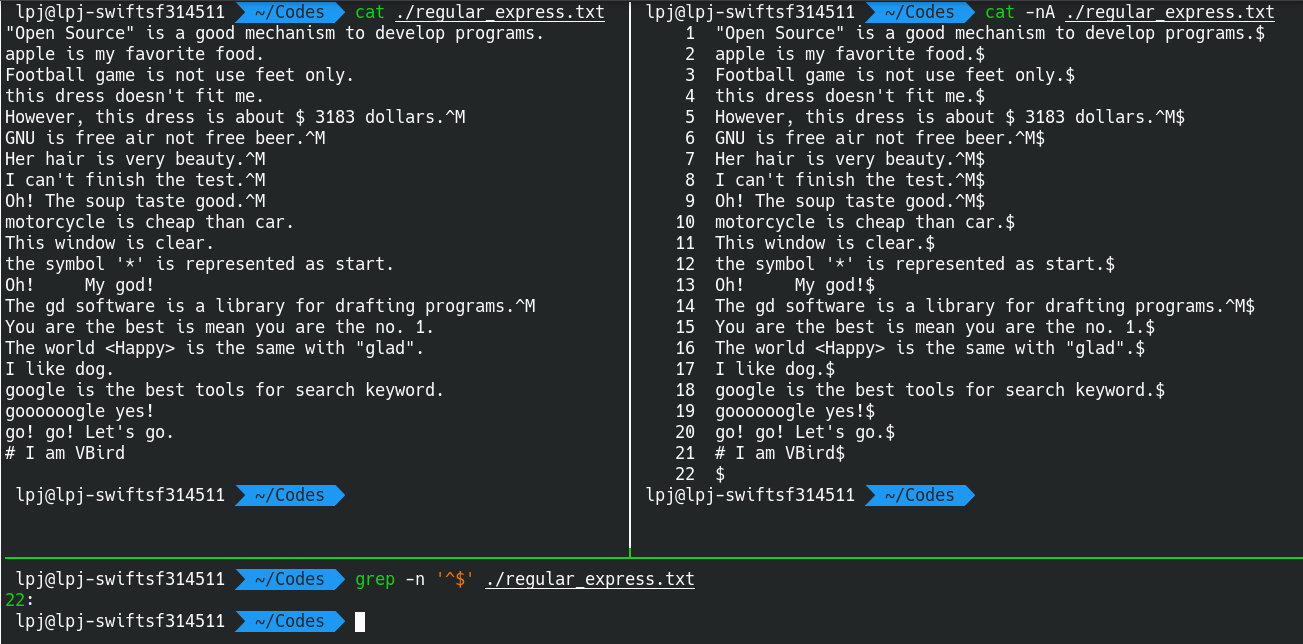
在 Linux 中,空行(hang) 就是 行(hang)首就是行(hang)尾定位符$
如果想去掉开头是#的行(hang)和空行(hang)以节省版面
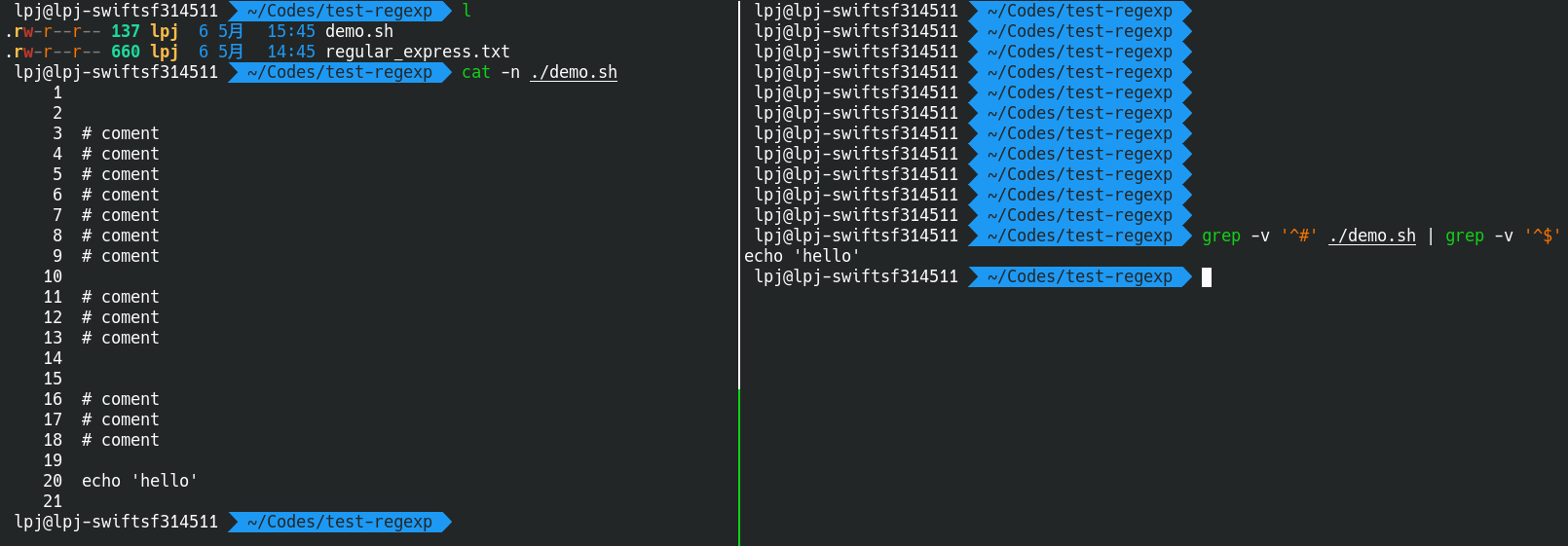
延伸型正则表达式
See here
Tools
格式化输出
资料处理
倾向于整行(行)处理 => sed
倾向于一行当中分成多个栏位来处理 => awk,相当适合处理小型的资料文件,多结合 printf 进行格式化输出
档案比对
档案列印准备工具(给档案加标题、页码、…)
(完)